

Tim MalcomVetter
Co-Founder / CEO
Type 1 and Type 2 Decisions
In his 2015 letter to Amazon shareholders, Jeff Bezos wrote:
Some decisions are consequential and irreversible or nearly irreversible – one-way doors – and these decisions must be made methodically, carefully, slowly, with great deliberation and consultation. If you walk through and don’t like what you see on the other side, you can’t get back to where you were before. We can call these Type 1 decisions. But most decisions aren’t like that – they are changeable, reversible – they’re two-way doors. If you’ve made a suboptimal Type 2 decision, you don’t have to live with the consequences for that long. You can reopen the door and go back through. Type 2 decisions can and should be made quickly by high judgment individuals or small groups.

Did you catch that? Jeff Bezos built Amazon on a mental model composed of these two types of decisions:
- Type 1: Consequential & Irreversible Decisions
- Type 2: Changeable & Reversible Decisions
#Decision Types in Cybersecurity
Jeff Bezos’ model is also very much how Wirespeed views the world of AI and cybersecurity decisions.
We wrote previously about the best Decision Systems for Cybersecurity. What we were focused on then was the best decision system to make automated decisions, or what we refer to as Verdicts, for security detections. We stood by then and still take the stance that conditional logic—putting in the work and building the algorithm, decision trees, and steps up-front, rather than short-cutting to ask a LLM to craft a workflow on the fly—is the absolute best approach. In fact, we think it’s the only approach that will scale and win the race to autonomous SOC (we’ll put another dollar in the jar for that egregious buzzword reference, sorry).
Detection Verdicts are Type 1 Decisions.
They’re crucial. No room for error.
In AQL, Acceptable Quality Limits (ISO 2859), terms, we use the verbiage: CRITICAL decisions; AQL mandates that defects affecting the safety of the users of a product are Critical Defects. If a detection’s verdict is incorrect, either by hallucination, classic software defect, or human error due to alert fatigue, the result is a defect affecting the safety of the organization being monitored, i.e. an attacker could breach the organization and wreak material impact uncontested and uncontained.
This is the absolute definition of a Type 1 Decision, which is why we firmly state:
There is no AI technology in existence today as we write this that we would trust to make these Type 1 Detection Verdict Decisions.
Apple recently backed up this position with their research and whitepaper on Large Reasoning Models: they’re just pattern matchers.
Will there ever be an AI technology that can do this? Maybe, but not today, nor on the horizon.
#Type 2 Security Decisions
But that’s not to say there aren’t excellent uses for AI! At Wirespeed, we use AI everyday, mostly for research and development assistance (and often clean up the code the AI model spits out, adding better edge case handling and architecture that only human expertise can provide).
But there’s the point: these are Type 2 Decisions.
- We can
CTRL+Zwhen the AI code generator gets hyperzealous and wipes out good code. - We can re-prompt when our research question about a security product or technology doesn’t yield the answer we wanted.
- We can undo a generative AI edit to a screenshot we want to share.
We can reverse these decisions, ergo they are Type 2.
To summarize, for automated decisions, if you can fully remove the human and leave them to bear the accountability of irreversibility, then they are truly Type 1 Decisions, but if you must have a human reviewer, they are Type 2 Decisions.
#AI for SecOps
The “success” of AI for SecOps startups resides completely in Type 2 Security Decisions:
- Co-Pilots are Type 2: re-prompt if you didn’t get the answer
- AI virtual Tier 1 analysts are Type 2 (Co-Pilots): because a human Tier 2 analyst will review the results to determine if they’re acceptable
- One AI SecOps company recently hosted an “AI SOC Competition”—not between one AI SecOps startup and another—but between teams of humans “guiding” a single AI SOC tool, i.e. Type 2 Decisions on full display
- Auto-Pilots are Type 1 because they truly make decisions (even if limited in scope) on their own without the opportunity to have human intervention.
- Many of our customers use Wirespeed as a Type 1 (or Autopilot) decision maker, but those decisions are made in conditional logic, not LLMs, ML, or other AI models.
It’s common to find an Enterprise SOC team focusing on DIY Detection Engineering over Purpose-Built Detection Products, where they want full control over every single step, not just the outcome, sometimes even at the expense of the outcome. Those are the ICP (ideal customer profile) buyers of AI virtual analysts. They want control. They want to review. They want a Co-Pilot. They want every security decision made by technology to be Type 2, reversible by them. The human security analysts get the final say. The human makes the Type 1 decision. The technology just speeds up the problem space to present the necessary information for the human to make the decision.
Those aren’t Wirespeed’s ICP (ideal customer profile). We cater to the customers who want the outcomes of fast & reliable security decisions, often coupled with automated containment decisions as well, with no tolerance for error. These are the people who:
- seek us out because of our stance on only using conditional logic for verdict decisions
- one year ago, felt like they couldn’t share their AI opinions openly for fear of ridicule
- became disenchanted after trying one or more AI SOC solutions
- or who just want a confident and competent security vendor who can monitor their environment, responding fast to threats, unafraid of free evaluations, and love running head-to-head competition (whether AI or teams of humans)
#So Wirespeed doesn’t use AI then?
No, we use AI selectively, sparingly, and only for Type 2 Decisions. LLMs are great at:
- remapping semi-structured data into new structures
- summarizing large amounts of data
- fixing up natural language grammar
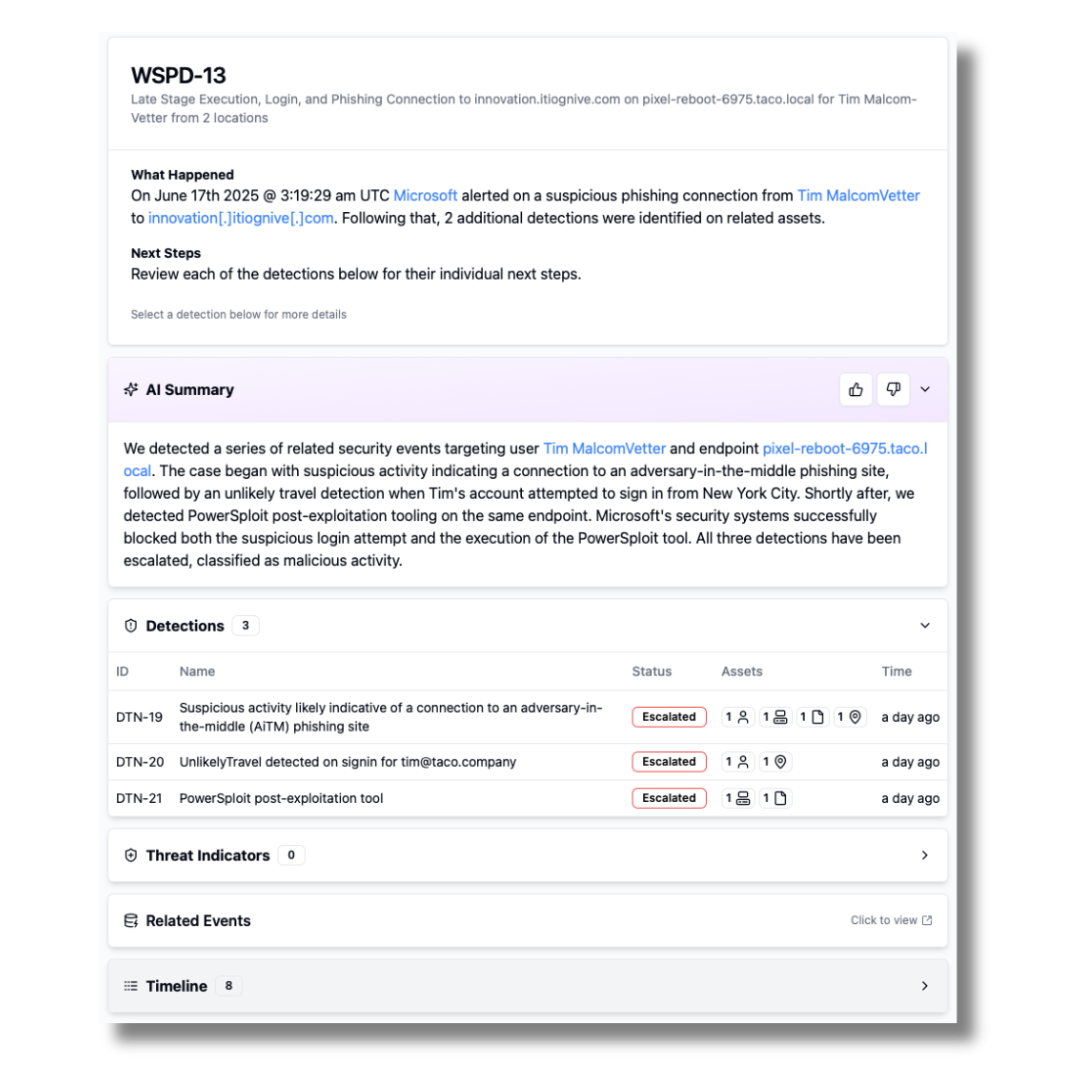
So, we use them in our product for these types of things. Just not to assign a verdict to a case. Here is an example complex case, involving multiple detections with a narrative AI summary. Literally everything else on the screen (and more importantly the transparently auditable decision steps) was generated by conditional logic, including the simple What Happened and Next Steps sections:
#Agentic Conditional Logic
In the hopes of making the market analysts’ heads spin a bit, Wirespeed is also busy adding Agentic Conditional Logic to our platform. We have asymmetric agents with unique purposes, but running conditional logic code that is very intentionally and discretely spun up when needed, to run follow-on processes in our parallel processing architecture. Agentic is not reserved only for AI. More on that for another time!
#What’s the Future of AI SOC?
Our prediction, is that in the next three years, the AI SOC vendors will look a lot more like Wirespeed.
For one, a couple of them have already been copying our product roadmap, citing features like AQL and ChatOps, but not actually showing the features in the UI. (Fine by us: it’s validation of our approach.)
They’ll initially (and likely have already started doing a tiny bit of this) quietly add in steps where conditional logic makes final decisions. They’ll come up with names and labels like “confidence thresholds” to pretend it’s somehow still in the realm of AI, but what they really mean is they’re limiting the decision-making authority of LLMs or LRMs or whatever AI acronym du jour, and taking some sort of numerical or objective output, rating, or score, from an AI model, that is then evaluated in a good old-fashioned if statement, like x > 90.
They’re already using collections of models, presumably from different foundational AI model vendors, trained in different ways. A common trap that AI afficionados often play is to chain models together. Don’t trust the output of one model? Chain another one to validate the output, basically gain an expensive and energy-consumptive “consensus” for a decision, and pretend its worthy of Type 1 status. This collection of models will subtly give way for more if statements and over time the architecture will be slimmed down, cutting the fat of many of the models.
Little by little, both by the rising cost of GPU compute and by the realization that customers mistrust the verdicts from their decisions, they’ll also start to realize that generating a whole workflow on every single alert is both wasteful and indicative that they don’t know how SOCs actually work. World class SOC teams have SOPs and discipline. What’s the old saying about professionals vs. amateurs?
Amateurs practice until they get it right. Professionals practice until they can’t get it wrong.
The only way to be a professional and not “get it wrong” is to have a well-engineered, as if sharpened by steel-on-steel through experience and time spent in-the-trenches of real SOCs, repeatable process. With a manual human-led SOC, world-class teams accomplish this through SOPs (Standard Operating Procedures), documentation, and auditing adherence to those SOPs. Wirespeed does it because we put in the work and converted those SOPs to code, complete with pre-defined edge case handling and everything.
That’s how we’re fast.
That’s how we’re repeatable.
That’s how we use AI.

Want to know more about Wirespeed? Follow us on LinkedIn / X or join our mailing list.