

Tim MalcomVetter
Co-Founder / CEO
Which Decision Making System is Best?
Over the past twelve months, I’ve observed a quietly growing sentiment amongst long-time cybersecurity practitioners: they know the GenAI hype isn’t living up to its fullest potential. Large Language Models (LLMs) are certainly here to stay. They have a place. They are a tool in the toolbox. But what is that place? If they’re not the right tool for us to reach higher levels of automation, let alone “autonomous,” how are defenders going to keep up with the scale and sprawl of technology growth and the constant opportunity for attackers to find unauthorized access?
#The Apple Whitepaper
Just a couple months ago, Apple released a whitepaper that broke down in technical terms what those of us using the technology daily have come to see firsthand. Apple co-author, Mehrdad Farajtabar, summarized LLMs as “sophisticated pattern matchers” in the paper:
Overall, we found no evidence of formal reasoning in language models including open-source models like Llama, Phi, Gemma, and Mistral and leading closed models, including the recent OpenAI GPT-4o and o1-series. Their behavior is better explained by sophisticated pattern matching—so fragile, in fact, that changing names can alter results by ~10%! We can scale data, parameters, and compute—or use better training data for Phi-4, Llama-4, GPT-5. But we believe this will result in “better pattern-matchers,” not necessarily “better reasoners.”
#Comparing AI to Databases in the 1990s
Another excellent take came from Harry Wetherald on LinkedIn, who suggested we time-travel to the 1990s, listen to the common questions from that era about “databases,” and replace “database” with “AI” to see the equivalency, so we can get a better handle or prediction around how the new technology will play out:
Will {databases/AI} capture a lot of value?
Yes.
Will {databases/AI} dominate all use cases?
No.
Will enterprise software essentially be a wrapper for {databases/AI}?
Yes.
Do we need cybersecurity, QA, and other controls for {databases/AI}?
Yes.
Should they be standalone categories like “Security for {databases/AI}”?
No.
Will {databases/AI} be integral to pretty much every B2B software product?
Yes.
And my personal favorite:
Will we stop talking about whether or not a product has {databases/AI} instead of just how good the product is?
Also Yes. (I’m looking forward to that!)
#So which decision-making process or tool should you use? And when?
Branching out into all flavors of “AI” (which is wrongfully used colloquially as a synonym for “LLM” in our current time), when is one approach superior to another? Well, like all things in life … it depends. Let’s look at two important attributes that help define the answer to this question:
- How well do you know the data? Dataset Comprehension
- How transparent do you need the answer to be? Transparency and Traceability
#Dataset Comprehension
Comprehension of dataset means that the engineers building the decision system have plenty of time, resources, and foreknowledge to know their dataset. They comprehend it. For a simplistic example with cybersecurity, let’s just suppose we’re building a system to determine if an observed event is good (benign) or bad (malicious, or at least very suspicious). In particular, let’s examine how much knowledge of the data set is required for each of the following approaches to work well, and let’s sort them starting with the approaches that require the highest level of dataset comprehension.
- Conditional Logic Algorithms
Conditional logic means if x do y. This approach requires the highest amount of domain specific knowledge in order to be highly effective. If changes happen to the dataset over time, such as changes in behaviors affecting cybersecurity decisions, the logic must be updated, but in exchange, it is fair to say that in an effective system (one that performs well at its purpose) using conditional logic requires understanding what is good or bad as well as how and why it is good or bad.
- Supervised Learning
Supervised Machine Learning (Supervised ML) requires the engineers building the system to have examples of labeled data in a “training” dataset, e.g. in our case these would be events, some of which are labeled as safe/benign and some are labeled unsafe/malicious. Every single item in that dataset must be labeled, but it is not a guarantee that every case found in a production environment will match the training set, which is where the ML comes in: it makes a decision about which label should be applied. Therefore, it’s fair to say Supervised ML requires less comprehension of the dataset than conditional logic.
- Large Language Models w/RAG
Let’s break LLMs into two separate high-level categories for the sake of this comparison. First, is essentially a customized or tuned instance of a LLM Foundational model. Foundational models are the ones that are available in open source and commercial flavors, versus a customized model built from scratch with its own complete training data set (a much less common deployment approach). RAG, or Retrieval Augmented Generation, is when a foundational model is supplied a repository of domain specific content, usually written in natural language (e.g. English), for the model to reference and prefer when generating responses over its default content in a standard foundational model. Because of the additional prep work with RAG, it’s fair to say that the engineers building it must at least have access to documentation of a decent level of comprehension over the dataset (although the engineer building isn’t required to have that comprehension, personally). This is similar to the amount of knowledge required for Reinforcement learning, but has the potential to be a higher amount given the RAG repository.
- Reinforcement Learning
Reinforcement Learning uses outcomes to reward or penalize a system for its decisions. There is no prior knowledge required on behalf of the engineers building the system. They simply define rewards and penalties, which are surrogates for safe or unsafe verdicts, in our example. This approach requires less comprehension of the dataset than supervised learning, which requires an adequate training set prior to deployment. All the builders need to know is the result of good or bad, not the what or the how, really just the why.
- Semi-Supervised Learning
Semi-Supervised Learning is like Supervised learning, only it has a training data set where not all items have labels. Since not all have labels, presumably because the builders didn’t have enough time or comprehension to properly label the content, Semi-Supervised ML clearly requires less dataset comprehension than Supervised ML. There’s also no outcome testing involved, like in Reinforcement Learning, so the developers don’t even have to comprehend why an event is safe or unsafe, in our example. It also doesn’t require a repository of natural language documents representing the missing knowledge, like LLMs, which further lowers the required comprehension of the dataset.
- Foundational Large Language Models
Foundational LLMs have standard general knowledge available to them, nothing domain specific. They make basic observations on the data in their model, by non-deterministically (i.e. with intentional randomness known as Stochasticity to appear more human and conversational). Because they require no special knowledge, the comprehension of the dataset is very low.
- Unsupervised Learning
Lastly, we have Unsupervised Learning, in which the engineers provide no insights into the comprehension of the dataset at design and implementation time, nor provide any feedback into its performance, like Reinforcement Learning. All Unsupervised ML does, really, is look at the attributes of data and attempt to group similar like items. Therefore, it demonstrates the lowest comprehension of the dataset. In cybersecurity, Unsupervised ML is used often for anomaly detection, and as is often the case, the system performing the detection does not know if the anomaly is good or bad, expected or unexpected. It can barely tell you why—and usually that is simply has to do with deviations from the rest of the population.
#Transparency and Traceability
If Dataset Comprehension was about demonstrating a command of the domain knowledge required to make the best decision, then Transparency and Traceability would be the opposite: being able to show your steps to prove your answer is correct. Let’s again take these same 7 approaches and rank them from most transparent and traceable to least. Note how some change order:
- Conditional Logic Algorithms
Once again, Conditional Logic Algorithms are on top of the list, because they require knowing the what, the how, and the why for each decision. Since the engineers must know the dataset well enough to make the decisions at design time, they also can easily add traceability for each step, and often do for troubleshooting to ensure correctness when testing the product before releasing it. Therefore, Conditional Logic has the highest possible traceability and transparency.
- Supervised Learning
For simpler Supervised ML models, like decision trees or linear regression, it’s very possible to trace why a decision was made based on the features of the input and the learnings from the training dataset. More complex supervised ML models like deep neural networks have a diminished transparency, therefore it’s overall transparency and traceability is lower than conditional logic approaches.
- Semi-Supervised Learning
Semi-supervised ML has a moderate amount of transparency, because many decisions can be traced back to the learning set, however the unlabeled data usually affects decision making in less clear ways, lowering both the transparency and traceability. That said, these decisions are typically repeatable, unlike LLMs, as detailed below.
- Reinforcement Learning
Reinforcement models learn a policy from interacting with the inputs in its environment. The dynamic nature of the learning can make it more challenging to show traceability and the complexity of the model can impact its transparency.
- Large Language Models
Both Foundational and RAG LLM models are black box approaches with very low transparency and traceability. They often have billions of parameters in their model, and generate stochastic (intentionally random) responses, based on chaining tokens together. All of this reduces transparency, increases complexity, decreases repetability, and makes tracing why an LLM made a decision very challenging overall. We gave examples of this in a prior blog post as well..
- Unsupervised Learning
Unsupervised Learning has the lowest transparency and traceability. Decisions from unsupervised methods, like clustering or dimensionality reduction, are based on finding patters or structures in the data, which aren’t great for making clear human-interpretable reasoning. There are also no explicit goals; the system is just told to “go.” If you’ve ever tried to use a map without a destination, you might also find tracing your steps and understanding why you made left and right turns to be a challenge.
#Composite Ranking
Taking these two sets of rankings, we get the following x-y (Cartesian plane) graph, that looks something like a Gartner Magic Quadrant, but for Decision Systems.
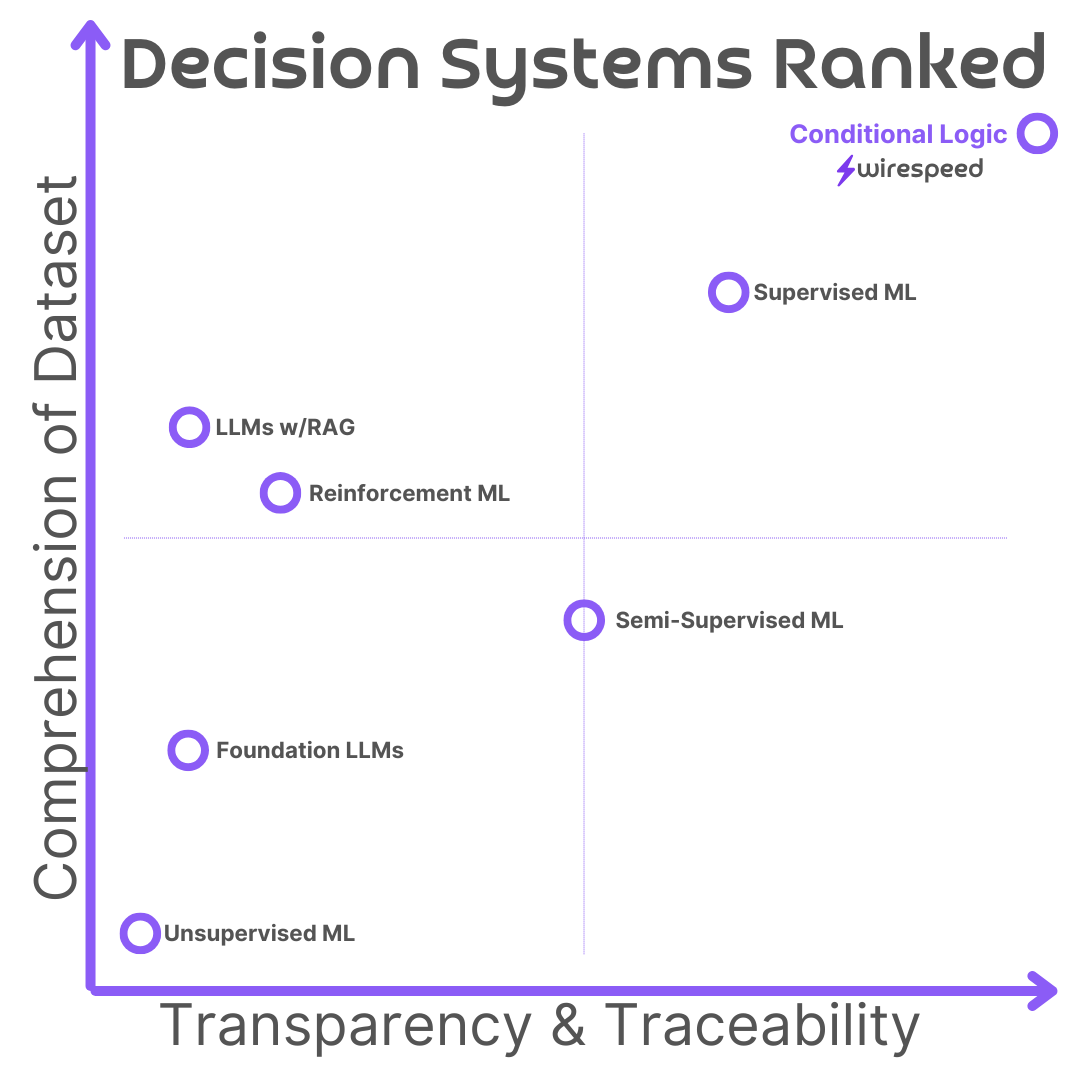
You’ll note Conditional Logic is in the top right corner, scoring the highest in both comprehension of dataset and transparency/traceability of decisions. This is why Wirespeed is built primarily using Conditional Logic: we understand the problem, the dataset, the what, how, and why cyber things are good and bad, and we want the transparency, traceability, and also in our case, the repeatability, of decision making that comes with Conditional Logic.
The second closest is Supervised ML, but at a considerable gap behind Conditional Logic. This makes sense: many cybersecurity products leverage Supervised ML to make detections, and many of those detections need to be triaged and cast aside as benign by humans in legacy SOC roles, or using Conditional Logic, like how Wirespeed does it.
Coming in the lowest overall, in the bottom left corner, is Unsupervised ML, followed by Foundation LLMs. This makes sense with what cybersecurity professionals experience overall: anomalies (the output of Unsupervised ML) are not high quality signal for security data, and Foundation LLMs are far from a replacement for a human SOC analyst. For that matter, neither are RAG LLMs, which can’t tell you why they made a decision, can’t repeat the decision with predictability (which is horrific for security), and this explains why no vendors offering “autonomous security operations” using RAG LLMs will boldly state they can replace a human SOC analyst in their decision making ability. (Instead, they merely tell you they can “reduce the load” by 80% or provide investigation assistance to a human analyst).
#Ensembles
Ensembles are the combination of more than one decision making process. Like looping an unsupervised model into a reinforcement model to help it find labels and groupings that might make sense. Or, using Supervised ML with a limited set of conditional logic decisions to reduce signals to a smaller, more accurate threshold.
Ensembles are the only way that solutions relying primarily on “GenerativeAI” (LLM variants) can perform well enough to be a saleable product. The LLM may be used to take unstructured, semi-structured, or unknown structured data, and transform it into a structure that a conditional logic rule can then process.
Another way to think of this: Conditional logic is the king of the data jungle; it’s just expensive to acquire the time and talent to codify it, and because it’s expensive, all the other approaches (Supervised ML, LLMs, Reinforcement, etc.) are just hacks to get closer to the precision of a well understood problem and dataset with conditional logic. This is why Wirespeed built its verdict engine on Conditional Logic, because it’s the best, most expressive, most definitive, most capable way of approaching the decision making process. Others building on AI/ML are cutting corners and hoping they’re “good enough” that you won’t complain.
In practice, everyone is using ensembles on some level. You’ll have a detection product that uses unsupervised learning to generate anomalies, then enrich them with another data set, maybe a second pass of something else, etc. Or perhaps an LLM will be used for a very narrow purpose, such as transcribing or extracting text into a well formed JSON object to be consumed by conditional logic or supervised ML. It’s ensembles all the way down. Even for Wirespeed customers, whose detection products employ a variety of these upstream of us.
#All things being equal
If all things are equal (cost, performance, compatibility, integrations, etc.), choose the solution that uses Conditional Logic at its core, with an ensemble of ML or LLMs for supportive, but non-decision-making functionality.

See the power of CONDITIONAL LOGIC in cybersecurity verdicts today: start a FREE TRIAL now.